
[ 지난 글 ] 에서 데이터 실수화와 변환에 대해서 다뤄봤는데
이번에는 1️⃣ 데이터 정제 2️⃣ 데이터 통합 3️⃣ 데이터 불균형 해결에 대해서 정리한다
🟣 데이터 정제 ( Data Cleaning )
- 결측 데이터 채우기 ex) np.nan, npNAN, none
➡️ 결측 데이터를 1️⃣ 평균 ( mean ) , 2️⃣ 중위수 ( median ) , 3️⃣ 최빈수 ( most frequent value ) 로 채움
from sklearn.impute import SimpleImputer
위의 코드를 사용해서 쓸 수 있다
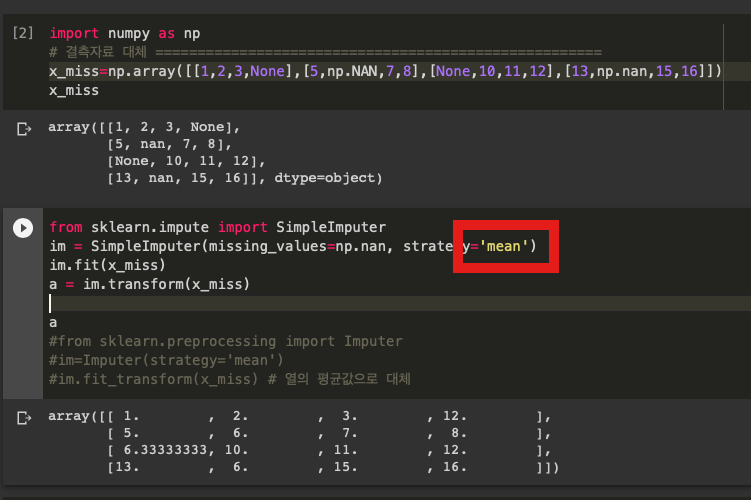
빨간 상자 부분을 바꿔서 평균, 중위수, 최빈수로 바꿀 수 있는데 각각 mean, median, most_frequent로 바꿀 수 있다
im.fit(x_miss)
a = im.transform(x_miss)이 부분은 im.fit_transform(x_miss) 로 바꾸도 똑같이 결과가 나온다
fit() : 훈련 데이터로부터 학습 모델 파라미터를 생성하는 데 사용
transform() : fit() 메소드에서 생성된 매개변수로, 변환된 데이터 세트를 생성하기 위해 모델에 적용
fit_transform() : fit() + transform을 한 번에

‼️ 아래 주석 처리해놓은 부분은 scikit_learn의 옛날 버전에서 사용하던 것이라 주석을 풀고 실행을 해도 오류가 뜬다
🔵 데이터 통합 ( Data Integration )
- 여러 개의 데이터 파일을 하나로 합치는 과정
- pandas의 merge() 함수 사용
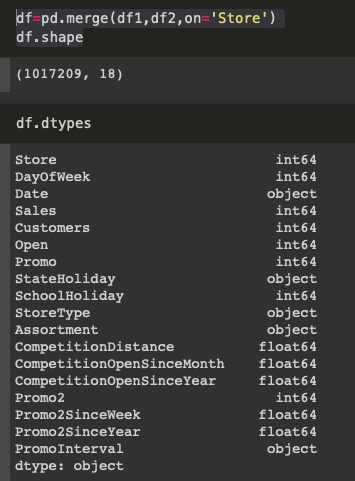
- pandas의 df.dtypes 로 변수의 변수 타입 확인 가능
데이터 1️⃣ ( 1017209 x 9 )

데이터 2️⃣ ( 1115 x 10 )

▶️ 통합 ( merge ) 후
🟢 데이터 불균형 해결 ( Data Imbalance )
❓ 데이터 불균형 이란
- 지난 글에서도 짧게 나왔지만 머신러닝의 목적이 분류일 때, 특정 클래스가 다른 클래스에 비해 매우 낮게 나타나면 불균형 자료라고 함
ex ) 🟥 - 10000개 🟧 - 50개 🟨 - 30개 ➡️ 🟧&🟨에 비해서 🟥이 너무 많음
✔️ 해결방법
1️⃣ 과소표집 ( undersampleing )
- 다수 클래스의 표본을 임으로 학습 데이터로부터 제거하는 것
- 위의 예시로 보면 🟥의 개수를 줄이는 것


2️⃣ 과대표집 ( oversampleing )
- 소수 클래스 표본을 복제하여 학습 데이터에 추가하는 것
- 위의 예시로 보면 🟧와🟨의 데이터를 추가하는 것
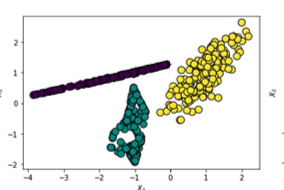
이를 확인해보기 위해서 코랩에서 분류용 가상 데이터를 만드는데
from sklearn.datasets import make_classification위의 코드로 만들 수 있다.
🔶 make_classification 의 인수
⏎ n_samples : 표본 데이터의 수, 디폴트 100
⏎ n_features : 독립 변수의 수, 디폴트 20
⏎ n_informative : 독립 변수 중 종속 변수와 상관관계가 있는 성분의 수, 디폴트 2
⏎ n_redundant : 독립 변수 중 다른 독립 변수의 선형 조합으로 나타나는 성분의 수, 디폴트 2
⏎ n_repeated : 독립 변수 중 단순 중복된 성분의 수, 디폴트 0
⏎ n_classes : 종속 변수의 클래스 수, 디폴트 2
⏎ n_clusters_per_class : 클래스 당 클러스터의 수, 디폴트 2
⏎ weights : 각 클래스에 할당된 표본 수
⏎ random_state : 난수 발생 시드
🔷 반환 값
⏎ X : [n_samples, n_features] 크기의 배열 ➡️ 독립 변수
⏎ y : [n_samples] 크기의 배열 ➡️ 종속 변수

2️⃣ - 노란색, 1️⃣ - 초록색 , 0️⃣ - 보라색
‼️ 잠깐 scatter 인수 정리 ‼️
plt.scatter( x축 , y축 , 어떤 모양으로 찍을지 (marker) , c ( 종속변수 , 여기서는 y ), s ( 사이즈 ), edgecolor ( 모양의 테두리 색), linewidth ( 테두리 두께 ))
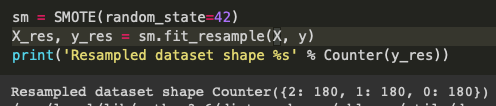
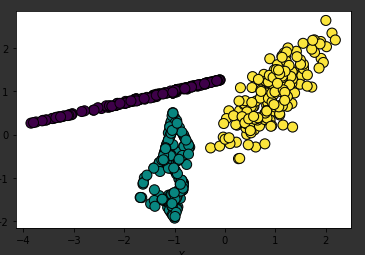
과대표집 방법 1️⃣ SMOTE
from imblearn.over_sampling import SMOTE위 코드 추가 후 아래와 같이 써준 후 plt.scatter을 사용해서 확인해보면 아래의 그림처럼 나옴
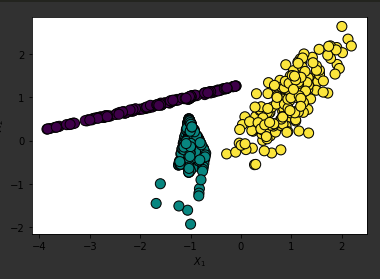
과대표집 방법 2️⃣ ADASYN
from imblearn.over_sampling import ADASYN위 코드 추가 후 아래와 같이 써준 후 plt.scatter을 사용해서 확인해보면 아래의 그림처럼 나옴

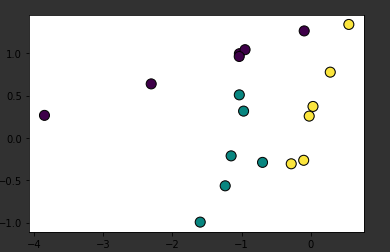
과소표집 방법
from imblearn.under_sampling import NearMiss
# define the undersampling method
undersample = NearMiss(version=3, n_neighbors_ver3=3)
# transform the dataset
X_Under, y_Under = undersample.fit_resample(X, y)위와 같이 써주고 plt.scatter을 사용해서 확인해보면 아래와 같은 그림이 나옴
'CODING > AI & ML & DL' 카테고리의 다른 글
| [기계학습] Bias - Variance Decomposition (0) | 2020.09.29 |
|---|---|
| [기계학습] 다중선형회귀 & 경사하강법 | Multiple Linear Regression & Gradient Descent (0) | 2020.09.28 |
| [기계학습] KNN | K - 최근접 이웃 알고리즘 (5) | 2020.09.21 |
| [기계학습/데이터 전처리] 1. 데이터 실수화 & 데이터 변환 ( 표준화 / 정규화 ) (0) | 2020.09.12 |
| [인공지능] Digit Recognizer | kaggle (ver.DNN) (0) | 2020.07.25 |




댓글