데이터 전처리란?
- 데이터의 품질을 올리는 과정
하는 이유는 ?
- 컴퓨터가 이해할 수 있는 값으로 변환해 주기 위해서
- ex) 남성 ➡️ 0 , 여성 ➡️ 1
- 불완전한 데이터 제거
- ex) NULL , NA , NAN 제거
- 잡음 섞인 데이터 제거
- 가격 데이터에 ➖ 값 제거
- 연령 데이터에 있는 큰 값 제거 ex) 200 , 300 •••
- 모순된 데이터 해결
- ex) 남성인데 주민번호 뒷자리 시작이 2인 경우
- 불균형 데이터 해결
- 클래스의 값이 너무 차이가 많이 나는 것을 해결
- ex ) 🅰️ - 10000개 🅱️ - 100개 ➡️ 이런 상황을 해결하기 위해
데이터 전처리 기법
🟢 데이터 실수화 ( Data vectorization )
- 범주형, 텍스트, 이미지 자료를 실수 형태로 전환하는 것
- 자료의 유형
- 연속형 - 100-90점 89-80점
- 범주형 - A형 B형 O형 AB형
- 텍스트 자료
1️⃣ 범주형 자료
1. one - hot encoding
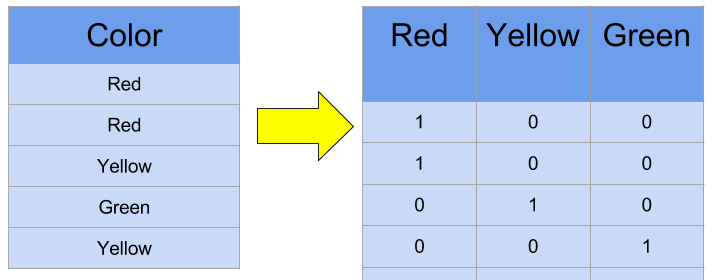
표현하고 싶은 단어의 인덱스에 1의 값을 부여하고 다른 인덱스에는 0을 부여하는 방법
2. scikit-learn / dictvectorizer 함수 사용
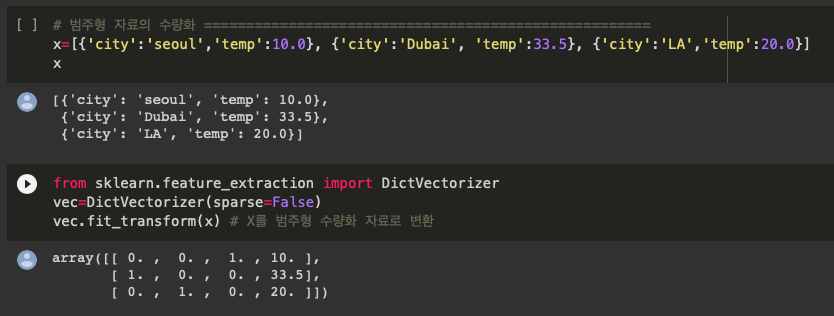
from sklearn.feature_extraction import DictVectorizerDicVectorizer(sparse=False) ➡️ defalut값의 sparse = True
➖true로 하게 되면 위와 같이 [ 0, 0 ,1 , 10 ], •••처럼 화면에 나오지는 않지만 메모리를 줄일 수 있음
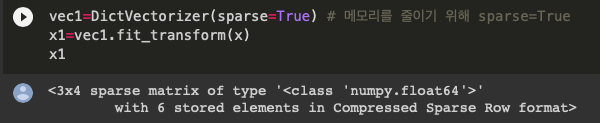
‼️ 여기서 나오는 sparse는 sparse matrix ( 희소 행렬 ) 에서 나온 것인데
희소 행렬이란 행렬의 값의 대부분 0인 경우를 말하는 것이고
불필요한 0 값으로 메모리 낭비도 심하고 크기가 커서 연산 시 시간도 많이 소모된다
➡️ COO(coordinate : 좌표 ) 형식 & CSR(compressed sparse row) 형식으로 해결
🌿CSR표현식이 메모리가 더 적게 들고 빠른 연산이 가능하여 더 많이 쓰임
2️⃣ 텍스트형 자료
1. 단어 출현 횟수를 이용
‼️ 출현 횟수가 정보의 양과 비례하는 것이 아니기 때문에 자주 등장하여 분석에 의미를 갖지 못하는 것 ( The , a 등 ) 의 중요도를 낮춰야 함
▶️ TF - IDF ( Term Frequency Inverse Document Frequency) 이용
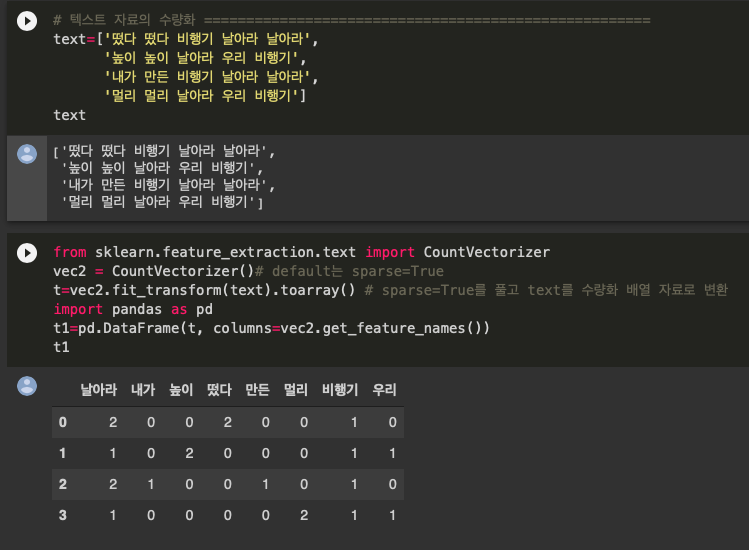
➡️ 여기까지는 그냥 등장 횟수를 샌 것 CountVectorizer을 이용
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer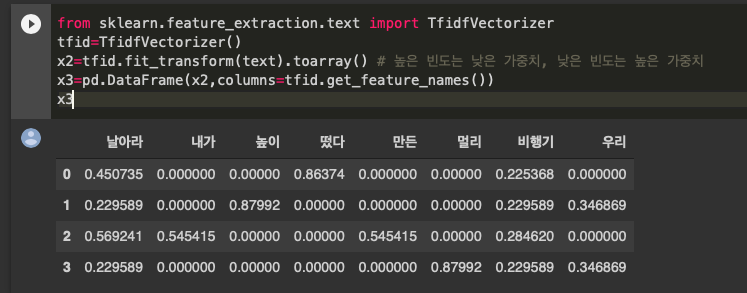
➡️ 여기서 TF - IDF 을 사용해서 높은 빈도에 낮은 가중치, 낮은 빈도에 높은 가중치를 줌
from sklearn.feature_extraction.text import TfidfVectorizer
🔴 데이터 변환 ( Data Transformation )
✔️ 머신러닝은 데이터가 가진 특성들을 비교하여 데이터 패턴을 찾는데 데이터가 가진 특성 간에 정도 차이가 심하면 패턴을 찾는데 문제가 발생함
1. 표준화 (standardization) 🔺 데이터 특성이 bell - shape 이거나 이상치가 있을 경우 유용
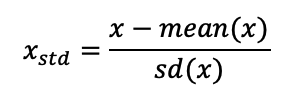
분모가 표준편차로 데이터가 평균으로부터 얼마나 떨어져 있는지로 나타내는 값
from sklearn.preprocessing import StandardScaler
2. 정규화 (normalization) ✔️ 보통은 표준화보다 유용함
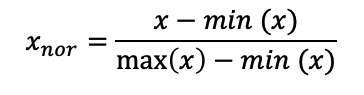
데이터의 상태적 크기에 대한 영향을 줄이기 위해 0 ~ 1 로 데이터 변환
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
여기까지 데이터 실수화와 변환이고 , 다음에는 데이터 균형, 데이터 통합, 데이터 정제 📝👩🏻💻
'CODING > AI & ML & DL' 카테고리의 다른 글
| [기계학습] Bias - Variance Decomposition (0) | 2020.09.29 |
|---|---|
| [기계학습] 다중선형회귀 & 경사하강법 | Multiple Linear Regression & Gradient Descent (0) | 2020.09.28 |
| [기계학습] KNN | K - 최근접 이웃 알고리즘 (5) | 2020.09.21 |
| [기계학습/데이터 전처리] 2 . 데이터 정제 & 통합 & 불균형 해결 (0) | 2020.09.14 |
| [인공지능] Digit Recognizer | kaggle (ver.DNN) (0) | 2020.07.25 |




댓글