Scaler 각 종류에 대해서 알아보기 이 전에 Scaler를 사용하는 이유에 대해 먼저 알아보자면
데이터가 가진 크기과 편차가 다르기 때문에 한 피처의 특징을 너무 많이 반영하거나 패턴을 찾아내는데 문제가 발생하기 때문
Scikit-learn에서 제공하는 여러 개의 Scaler중에 4가지를 알아볼 것이다.
1. Standard Scaler
⚫ 기존 변수의 범위를 정규 분포로 변환하는 것.
⚫ 데이터의 최소 최대를 모를 때 사용
⚫ 모든 피처의 평균을 0, 분산을 1로 만듬
⚫ 이상치가 있다면 평균과 표준편차에 영향을 미치기 때문에 데이터의 확산이 달라지게 됨
➡️ 이상치가 많다면 사용하지 않는 것이 좋음
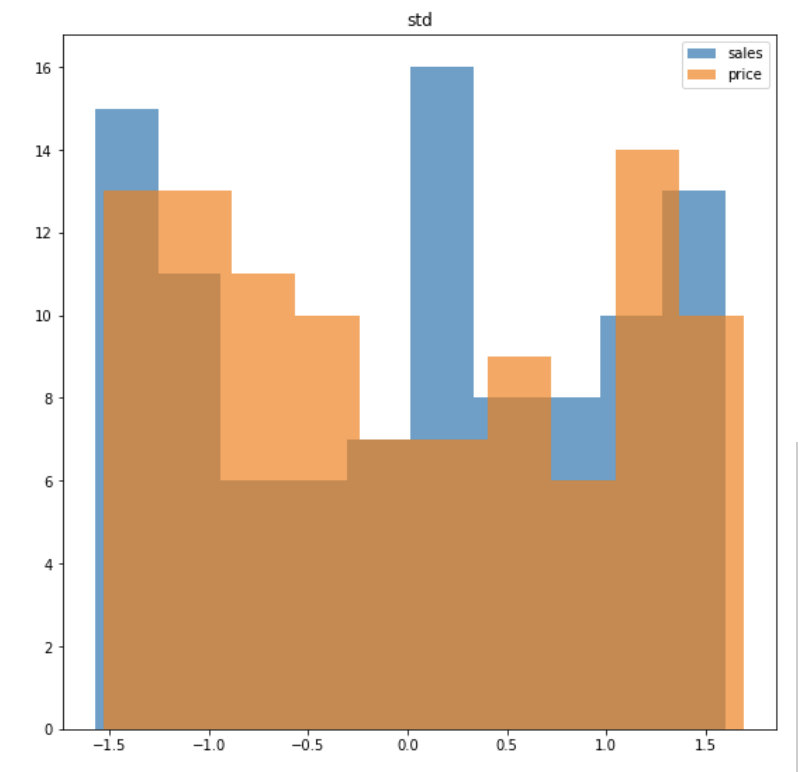
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
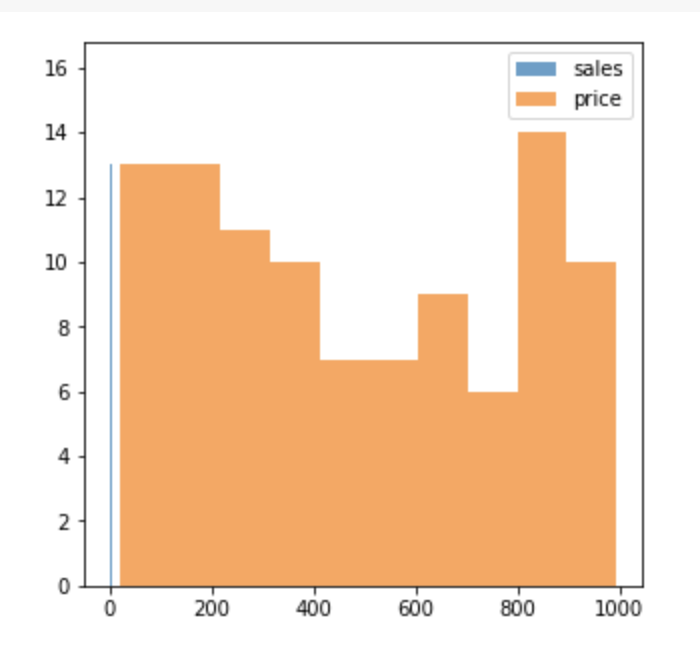
std_data = std.fit_transform(data)ex ) 최대 - 최소의 범위가 0.04 ~ 3.49인 sales & 최대 - 최소 범위가 22.43 ~ 994.98인 price
2. Normalizer
⚫ 각 변수의 값을 원점으로부터 1만큼 떨어져 있는 범위 내로 변환
➡️ 빠르게 학습할 수 있고 과대적합 확률을 낮출 수 있음
from sklearn.preprocessing import Normalizer
nor = Normalizer()
nor_data = nor.fit_transform(data)
ex ) 최대 - 최소의 범위가 0.04 ~ 3.49인 sales & 최대 - 최소 범위가 22.43 ~ 994.98인 price
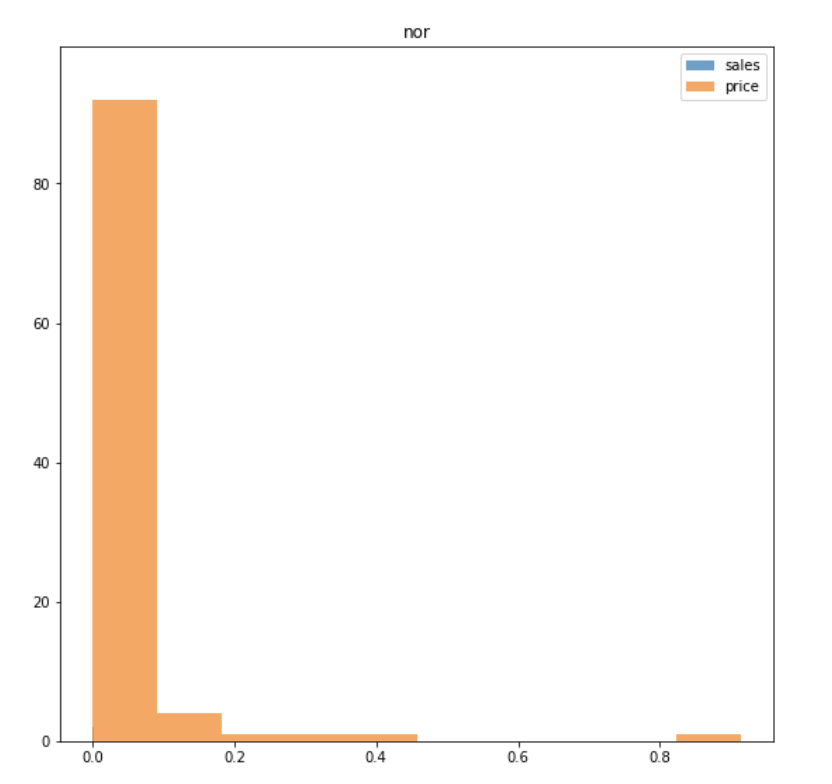
데이터가 normalizer에 적합하지 않았던 것 같다.
3. MinMaxScaler
⚫ 데이터의 값들을 0~1 사이의 값으로 변환시키는 것
⚫ 각 변수가 정규분포(bell-shape)가 아니거나 표준 편차가 작을 때 효과적
BUT Standard Scaler와 같이 이상치 존재에 민감
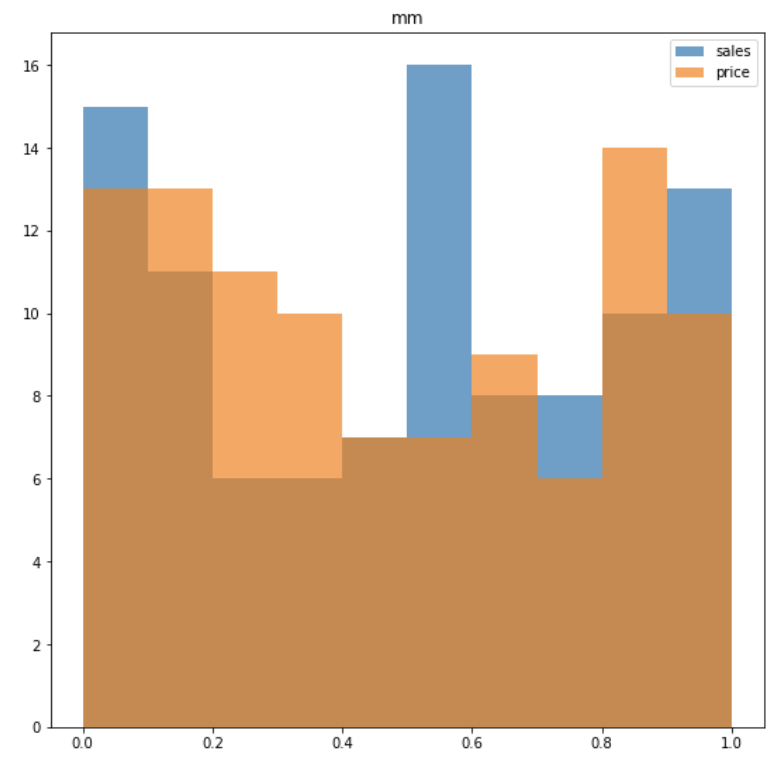
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
mm_data = mm.fit_transform(data)ex ) 최대 - 최소의 범위가 0.04 ~ 3.49인 sales & 최대 - 최소 범위가 22.43 ~ 994.98인 price
4. Robust Scaler
⚫ 모든 피처가 같은 크기를 갖는 다는 점이 standard와 유사
⚫ BUT 평균과 분산이 아닌 중위수(median)과 IQR(사분위수)를 사용함
➡️ Standard scaler에 비해 이상치의 영향이 적어짐
from sklearn.preprocessing import RobustScaler
rob = RobustScaler()
rob_data = rob.fit_transform(data)
ex ) 최대 - 최소의 범위가 0.04 ~ 3.49인 sales & 최대 - 최소 범위가 22.43 ~ 994.98인 price
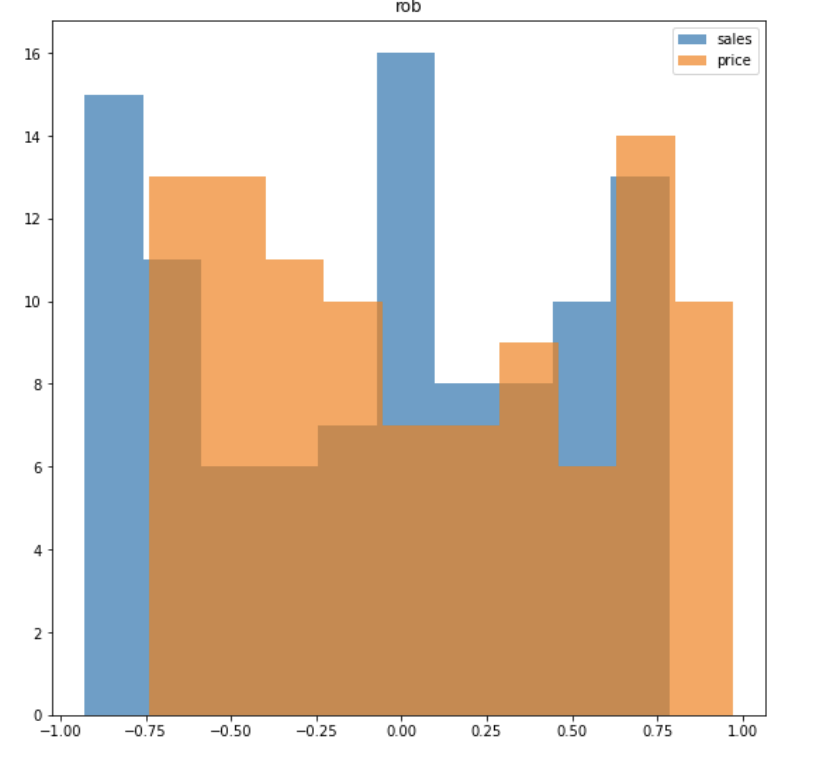
Scaler를 사용해서 feature간의 크기를 유사하게 만드는 것은 중요하긴 하지만 모든 feature의 분포를 동일하게 만들 필요는 없다.
데이터가 한 곳에 집중되어 있는 데이터를 표준화 시키면 큰 차이를 만들어내 버릴 수 있기 때문에 데이터에 맞게 스케일링할 필요가 있다.
'CODING > AI & ML & DL' 카테고리의 다른 글
| Precision과 Recall의 차이 및 예시 (0) | 2022.05.22 |
|---|---|
| [MacOs / Error] xcrun: error: invalid active developer path 해결법 (0) | 2022.02.13 |
| [Python/데이터분석] 상관계수 해석 (0) | 2021.09.05 |
| [NLP] python / Keras를 사용한 챗봇 만들기 (0) | 2021.06.06 |
| [ML] BoVW : bag of visual words | Feature engineering (1) | 2020.12.22 |




댓글