[ 지난 글 ] 에서 판별 분석에 대해서 다뤄봤는데, 이번에는 판별 분석 중에 선형 판별 분석에 대해 정리해보자
선형 판별 분석 [ Linear Discriminant Analysis ]
- 데이터를 특정 한 축에 사영(projection)한 후에 두 범주를 잘 구분할 수 있는 직선을 찾는 것이 목표
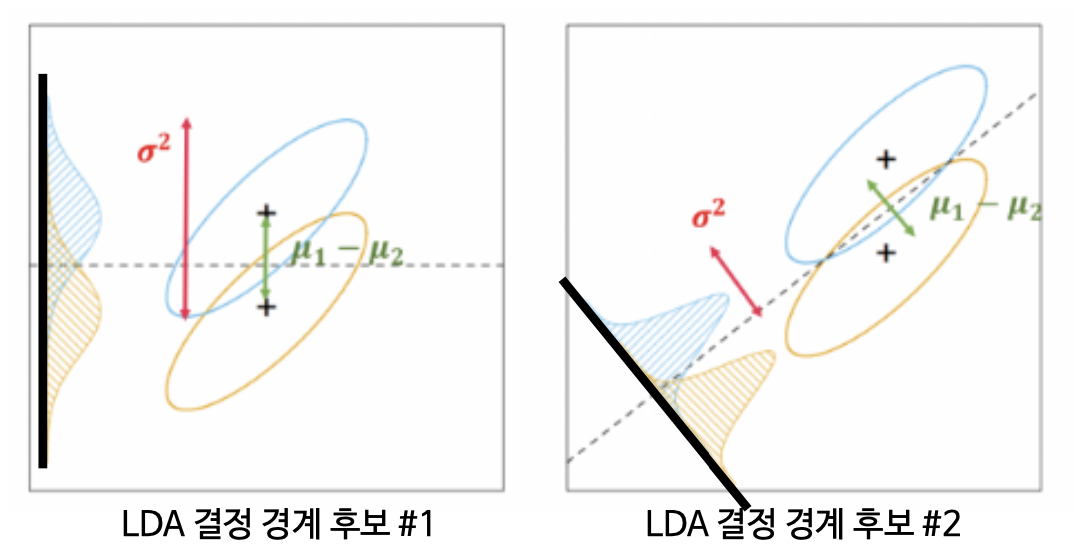
위의 경우 왼쪽보다 오른쪽이 더 분류가 잘 됐다고 판단
가정 ( Assumptions )
- 아래의 가정을 만족해야 이 모델을 사용할 수 있다.
1️⃣ 각 클래스 집단은 정규분포 ( normal distribution ) 형태의 확률분포를 가짐
2️⃣ 각 클래스 집단은 비슷한 형태의 공분산 ( covariance ) 구조를 가짐
➡️ 각 클래스 집단 모두가 아래의 3가지 형태중 한가지 형태를 띄워야 함
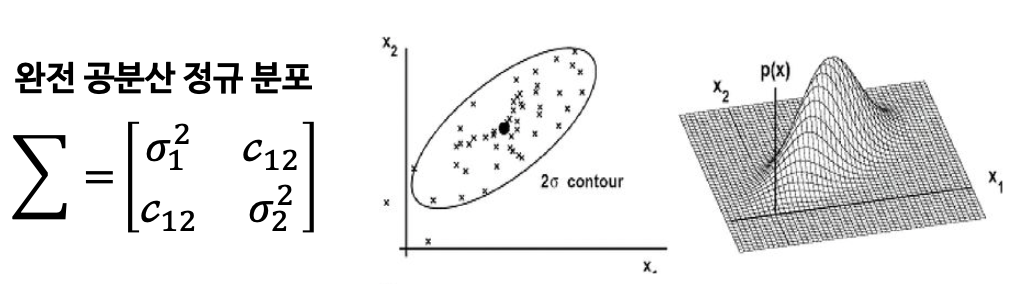
🧩 공분산
- 2개의 확률변수의 상관 정도를 나타내는 값
공분산의 3가지 유형
1️⃣ 완전 공분산 정규 분포
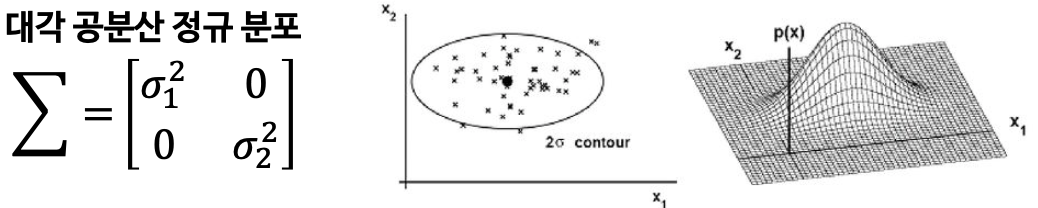
2️⃣ 대각 공분산 정규 분포
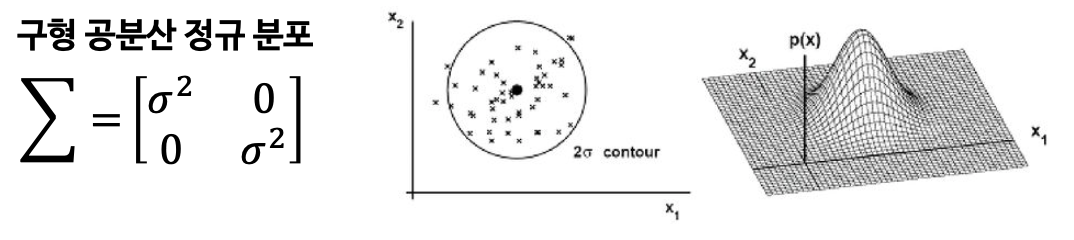
3️⃣ 구형 공분산 정규 분포
💡 LDA는 판별 + 차원 축소의 기능을 한다.
2차원 ( 2가지 독립변수 )의 2개의 클라스를 갖는 데이터를 분류하는 문제에서 LDA는 먼저 하나의 차원( 1d )에 사영(projection) 하여 차원을 축소시킨다.
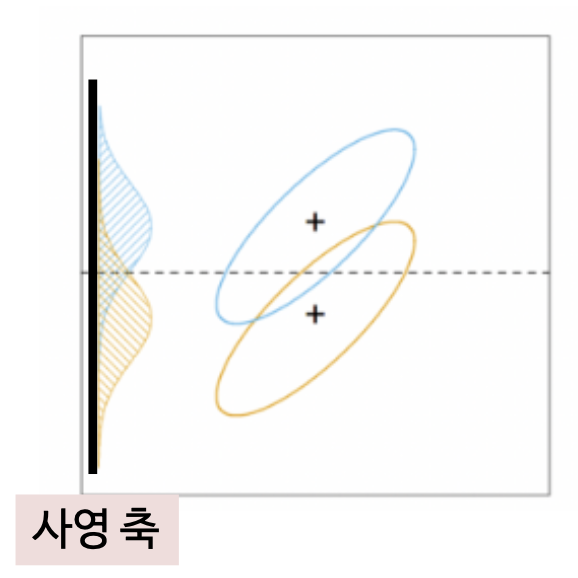
LDA의 결정 경계 (decision boundary)
사영축 ( = 아래의 그림에서 검은 실선 ) 에 직교하는 축 ( = 아래의 그림에서 회색 점선 )
정사영은 두 분포의 특징이 아래의 목표를 달성해야함
📌 각 클래스 집단의 평균의 차이가 큰 지점을 결정 경계로 지정 ▶️ 아래의 그림에서는 초록 선이 긴 것
📌각 클래스 집단의 분산이 작은 지점을 결정 경계로 지정 ▶️ 아래의 그림에서는 빨간 선이 짧은 것
➡️ 분산 대비 평균의 차이를 극대화 하는 결정 경계를 찾고자 하는 것

‼️[ TIP❗️] 사영 데이터의 분포에서 겹치는 영역이 작은 결정 경계를 선택하는 것 ‼️
장점
1️⃣ 변수 간 공분산 구조를 반영
2️⃣ 공분산 구조가 가정이 살짝 위반되더라도 비교적 robust하게 동작함
단점
1️⃣ 가장 작은 그룹의 데이터 개수가 독립변수의 개수보다 많아야함 ➡️ 판별분석의 기본적인 조건 [ 이전 글 : 표본의 크기 ]
2️⃣ 정규분포가 가정에 크게 벗어나는 경우 잘 동작하지 못함
3️⃣ 범주사이 ( Y )에 공분산 구조가 많이 다른 경우를 반영하지 못함 ➡️ 이차판별분석법(QDA)를 통해 해결 가능
[ 파이썬에서 ' IRIS 데이터 ' LDA에 적용 ]
1️⃣ Iris 데이터 불러오기 + test / train 데이터로 나누기
# Iris data 불러오기
import seaborn as sns # seaborn을 불러옴.
iris=sns.load_dataset('iris') # iris라는 변수명으로 Iris data를 download함.
X=iris.drop('species',axis=1) # 'species'열을 drop하고 특성변수 X를 정의함.
y_=iris['species'] # 'species'열을 label y를 정의함.
from sklearn.preprocessing import LabelEncoder # LabelEncoder() method를 불러옴
classle=LabelEncoder()
y=classle.fit_transform(iris['species'].values) # species 열의 문자형을 범주형 값으로 전환
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y, test_size=0.4, random_state=123, stratify=y)
2️⃣ LDA를 사용하기 위해 sklearn.discriminant_analysis에서 LinearDiscriminantAnalysis 임포트
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
cld=LinearDiscriminantAnalysis(store_covariance=True)
3️⃣ 적용 후 정확도 확인
cld.fit(X_train, y_train) # LDA 적합
y_train_pred=cld.predict(X_train)
y_test_pred=cld.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(y_train, y_train_pred)) # train data에 대한 accuracy
print(accuracy_score(y_test, y_test_pred)) # test data에 대한 accuracy'CODING > AI & ML & DL' 카테고리의 다른 글
| [기계학습] 의사결정나무 | Decision Tree (0) | 2020.10.30 |
|---|---|
| [기계학습] 이차 판별 분석 | Quadratic Discriminat Analysis (0) | 2020.10.15 |
| [기계학습] 판별 분석 | Discriminant analysis (0) | 2020.10.13 |
| [기계학습] 로지스틱 회귀 | Logistic Regression (2) | 2020.09.30 |
| [기계학습] Bias - Variance Decomposition (0) | 2020.09.29 |




댓글